AI_YOLO 教室智慧監視系統
資訊專案結構說明
本專案採用三層模組化架構,確保高效能、低延遲與可擴展性,適用於複雜的教室智慧監控場景。
- Core Logic Layer:核心處理模組,整合 YOLOv8 物件偵測引擎與 MediaPipe 特徵點計算管線,負責所有 AI 推論任務。
- Capture Layer:影像擷取層,透過多線程優化 OpenCV 讀取速度,有效降低影格延遲,確保串流穩定性。
- Data Interface Layer:資料介面層,將所有辨識結果(Bounding Box、骨架節點、人數統計)即時渲染至輸出畫面,並記錄事件時間軸。
系統環境圖 (UML) 與程式邏輯說明
程式邏輯:系統啟動後初始化相機硬體與 AI 模型權重,接著進入主迴圈執行五段式管線——讀取影格 → 影像預處理(縮放、色彩空間轉換)→ AI 批次推論 → 繪製辨識結果 → 輸出串流。異常事件會同步寫入事件時間軸進行記錄。
Web Camera 功能測試 ✓ SUCCESS
測試目的:確認影像能正確從硬體讀取,並成功顯示於 OpenCV 視窗中,驗證相機驅動與 Python 環境的整合正確性。
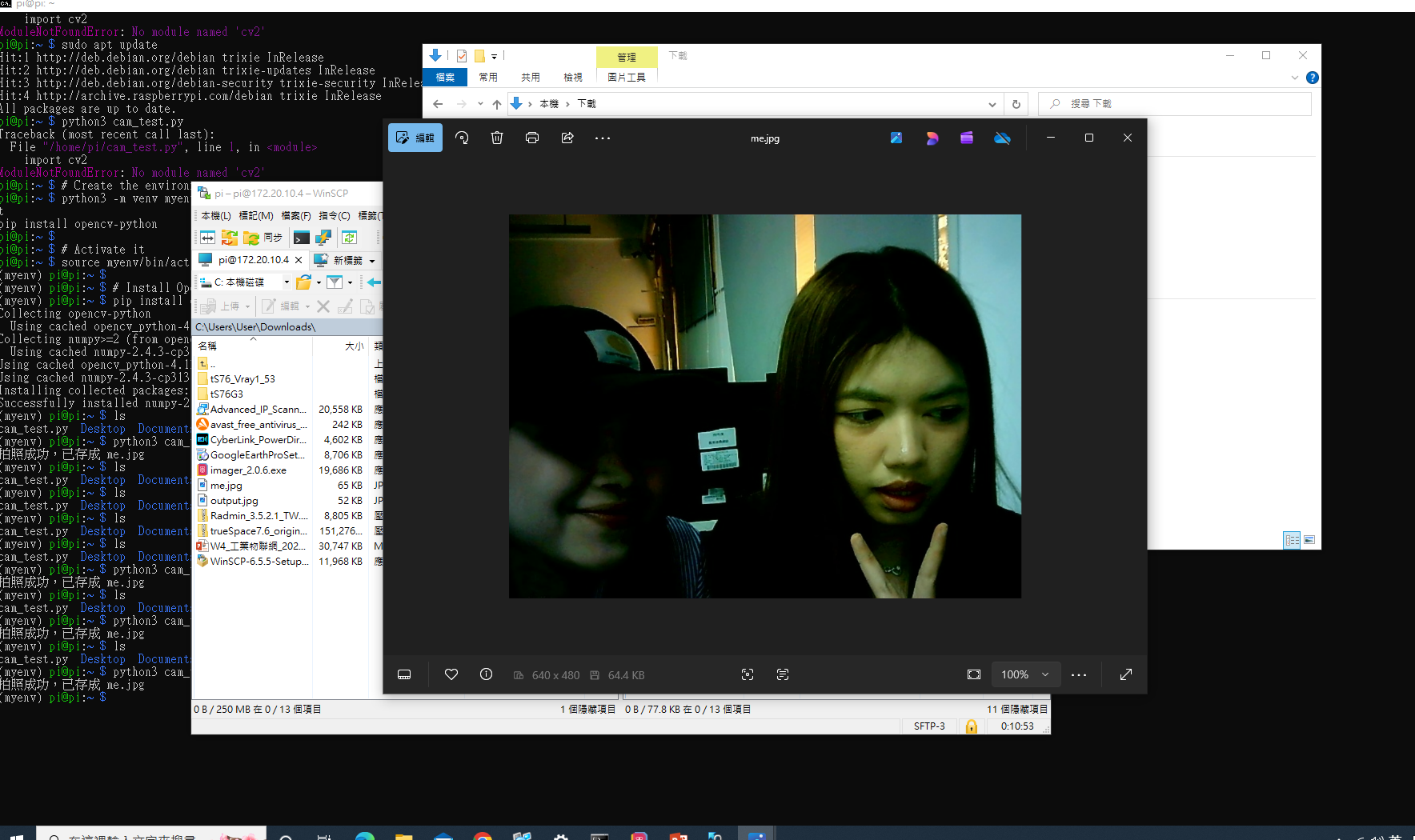
測試結果:成功取得穩定影像流,解析度設定正常,無斷訊或影格撕裂現象,延遲低於可接受閾值。
YOLO 物件偵測 功能測試 ✓ SUCCESS
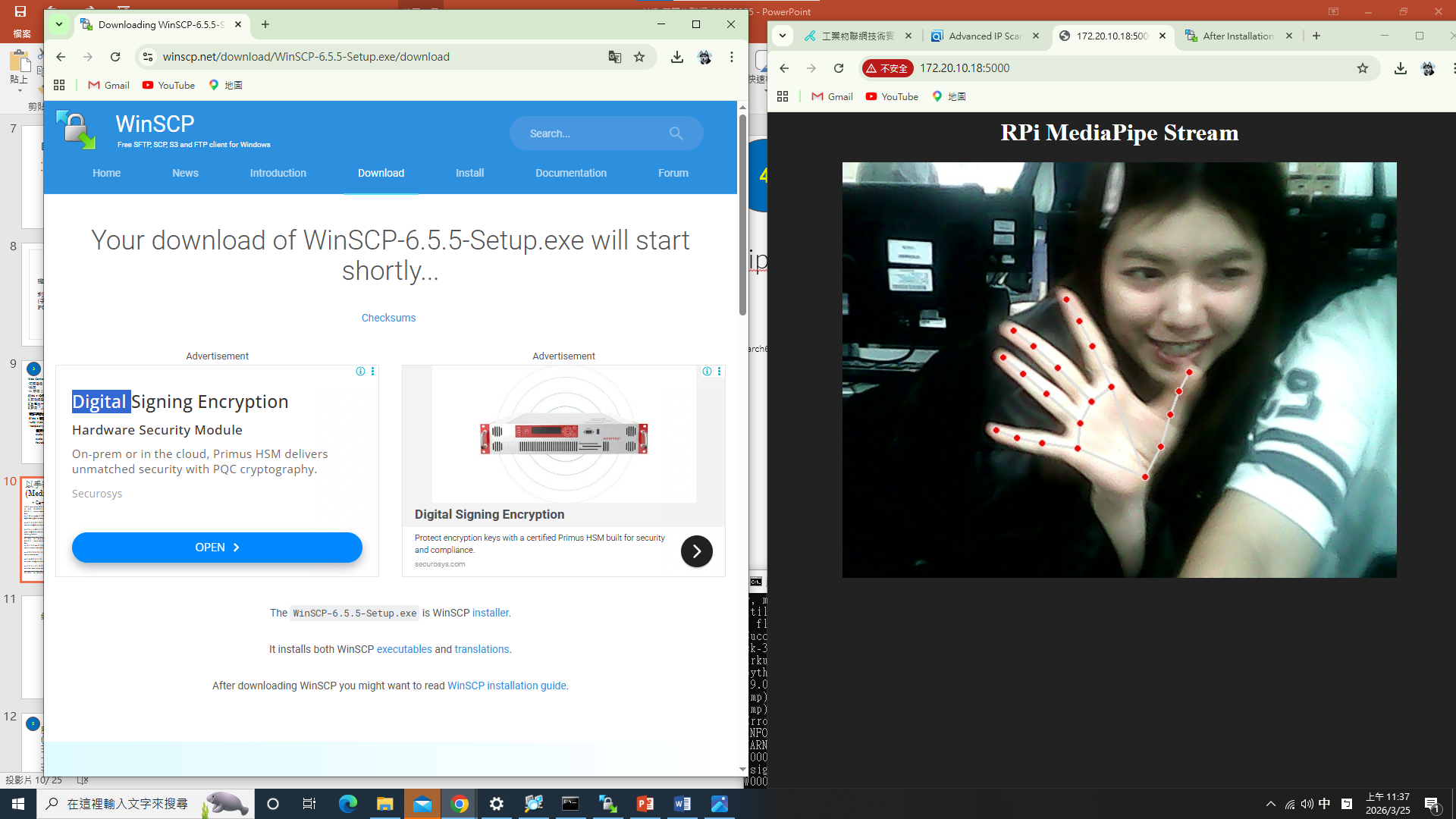
說明:針對教室內物件(person、chair、laptop 等 COCO 類別)進行即時偵測與分類,每個偵測框附帶類別標籤與信心數值(Confidence Score),偵測效能穩定,多目標同框表現良好。
手部偵測 (MediaPipe) 功能測試 ✓ SUCCESS
說明:利用 MediaPipe Hands 模型追蹤手部 21 個關鍵骨架節點,骨架連線清晰穩定,可應用於舉手行為偵測或手勢分析,為後續互動行為辨識奠定基礎。
臉部網格偵測 功能測試 ✓ SUCCESS
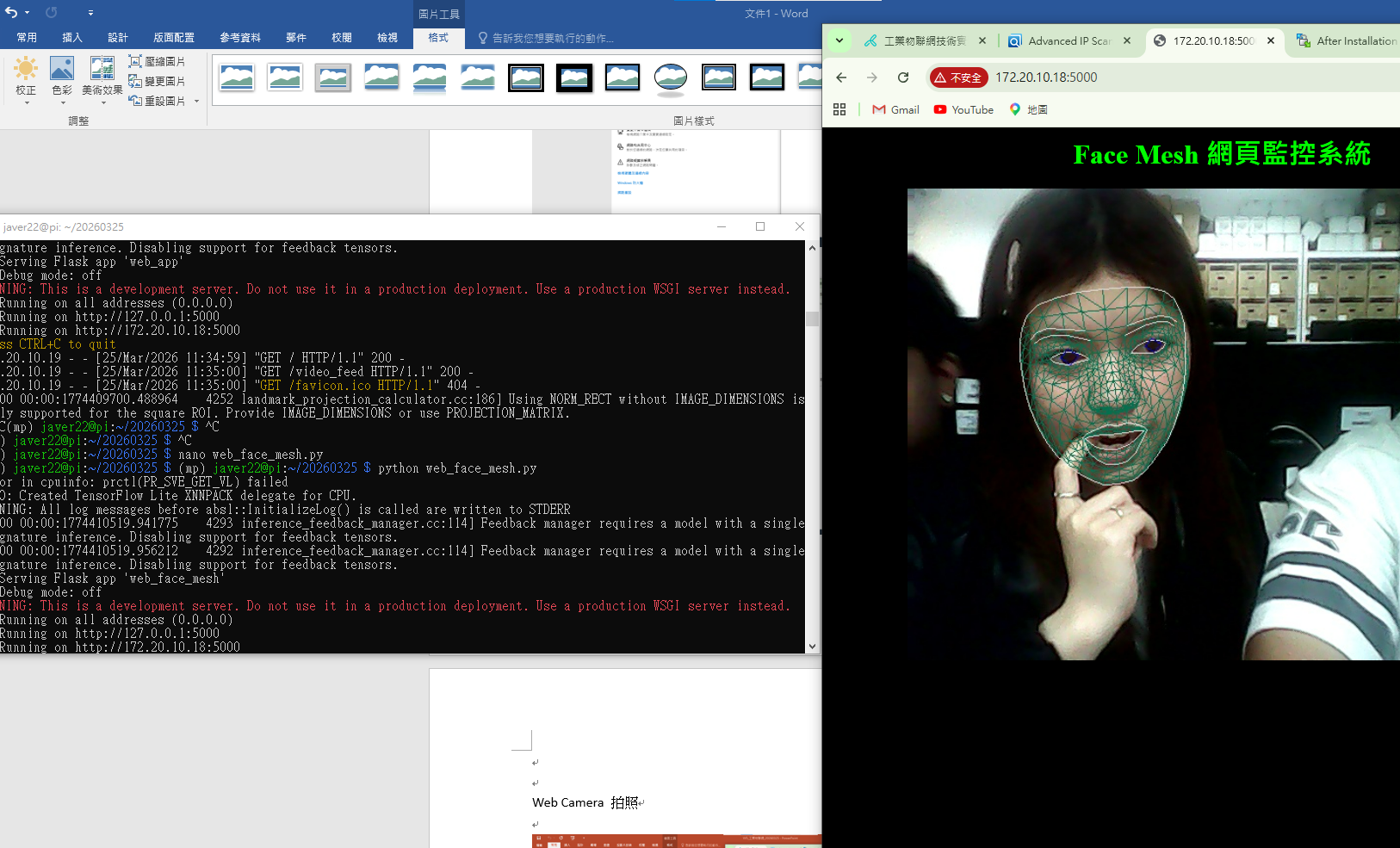
說明:透過 MediaPipe Face Mesh 進行精細的 468 點臉部特徵點定位,節點密集且追蹤穩定,可應用於眼睛開合度(專注度分析)、頭部姿態估測或表情辨識等進階功能。
全系統功能清單
使用 AI 工具對話連結
本專案開發期間使用 Gemini 進行環境排錯與程式碼優化,以下為完整對話紀錄:
- OpenCV 環境除錯: Gemini 對話紀錄 — 關於 cv2 模組與虛擬環境配置問題
Trouble Shooting 與學習心得
主要錯誤排除紀錄
Root Cause:系統中存在多個 Python 解譯器版本,程式執行時調用了未安裝 OpenCV 的全域環境,而非預期的虛擬環境。
解決方案:透過 which python 確認當前解譯器路徑,切換至正確虛擬環境後,執行 pip install opencv-python 完成部署。此後建立養成習慣:每次開發前先確認環境啟動狀態。
學習心得:困境鍛造能力
在製作這個專案的過程中,我深刻體會到「萬事起頭難」絕不是一句空話,而是每一位開發者都必然走過的試煉。
開發初期,光是建置 Python 虛擬環境便耗費了大量時間。路徑衝突、套件版本不相容、解譯器指向錯誤——每一個看似微小的環境問題,都足以讓整個系統無法啟動。當 No module named 'cv2' 的錯誤反覆出現時,那種挫敗感是真實且沉重的。
進入 AI 模型整合階段後,挑戰更加複雜。YOLO 的參數調整、MediaPipe 與影像管線的整合、多模組同時執行時的效能瓶頸……每一個問題都需要大量查閱文件、反覆實驗與重構。但也正是在這個過程中,我真正學會了如何系統性地 Debug:先隔離問題範圍,再針對性地查找解決方案,而非無目的地反覆嘗試。
當畫面第一次成功圈出物件、手部骨架節點精準地隨手移動時,那種難以言喻的成就感,是所有挫折最好的回報。這次專案讓我理解:真正的學習,往往藏在那些讓你幾乎想放棄的時刻之後。